

The Eternal Recurrence of DevOps
Embrace the post-kubernetes DevX platform rewrite, but, please, without RIP'ing us olds.
Suggested episode theme song:
The Eternal Recurrence of DevOps


Earlier today, I was “seems kind of stupid”’ing us all rebuilding PaaSes (or, here if you prefer). This is a popular response us olds have to “platform engineering.” I mean, to my fellow PaaS Warriors, sure - 💯 and all that. Fist bump.
But, let’s YES AND it! As I went over back at DevOpsDays DFW last year, I’m cool with it: smoke ‘em if you gotta ‘em.
That’s because I believe that we reinvent the app stack every five to ten years. It’s like a force of nature - a real King Canute situation. Us olds need to get over it, and the yutes need to build from the lessons learned last time.
Why We Keep Rewriting the Stack
App stack reinvention happens for at least two reasons.
First, when you get the infrastructure layer changes, it’s an upwards leaky abstraction. You have to change the application and even UI layers to cope with and take advantage of the new infrastructure. You go from GUI, web, mobile because of desktop, Internet, fast cell networks and “phones.” You move from mainframe, to Unix, (and mini for a bit), to Windows, to Linux, to virtualization, to IaaS, and maybe, one day, when Wardley’s dreams finally come true, serverless.
Once - as - each of these new infrastructure layers took over, the app stacks above them changed. We don’t do JSPs anymore, but, boy, they were a thing for a long time. I don’t even know what the last five or ten years of UI layers have been or currently are. Is JavaScript still a thing? We’re supposed to hate node.js now, right? Do the kids like the box model? Fuck if I know.
This dynamic drives everything.
Systems management/monitoring/log management and all that. (I read enough to know that I can't add in “observably” BECAUSE THAT IS WRONGTHINK. So.) Here, we had PATROL, synthetic web transaction monitoring (APM), SaaS APM, log management, and now…<cough> that word I’m not supposed to use. Configuration management is the same: Bladelogic, Puppet/Chef, BOSH, yaml. Release management…I don’t know, like, apt-get, to Maven, to npm, Docker, to, yaml…and now…CUE and stuff, well, sort of. Throw some ITIL and CMDB in there and you got a stew goin’. The systems management layer always changes as the infrastructure layer under it changes.
Why don’t the existing app stack layers just get updated to play nicely? Well, that’s reason two.
Second, the people who built and used the previous app stack layer move on. They’re promoted to management/architecture, they retire. They get kids and don’t have energy and time for workplace, uh, optimism. They cash out their current startup and need to do something different at a new one (this happens in the systems management space to a sad/comical degree).
Then the new people come in, look at what the olds built and are like “what is this pile of shit?” If you’ve ever been a developer you know that - despite what best practices try to tell you - it’s sometimes better to just re-write a 3 to 5 year old codebase rather than take the time to understand and extend it. I mean: does it even have trustworthy test suites in place? And when it’s not a good idea to do rewrite everything, aversion to boredom wins over still: people who build software want to build software, not just Schneider someone else’s code base.
And then add in the need for new vendors (and don’t think just because you’re an open source project you can escape this same thing) to, you know, have something new to sell (or be stared in GitHub, or whatever), and you can start to see why the app stack gets rebuilt in each infrastructure cycle.
Thus, we arrive at the “well, I guess we’re rebuilding all that PaaS stuff from the late 2010’s” I was shit-posting about while sipping my second cup of coffee this morning.
Current Status
Here’s the crude timeline I put together for that talk:
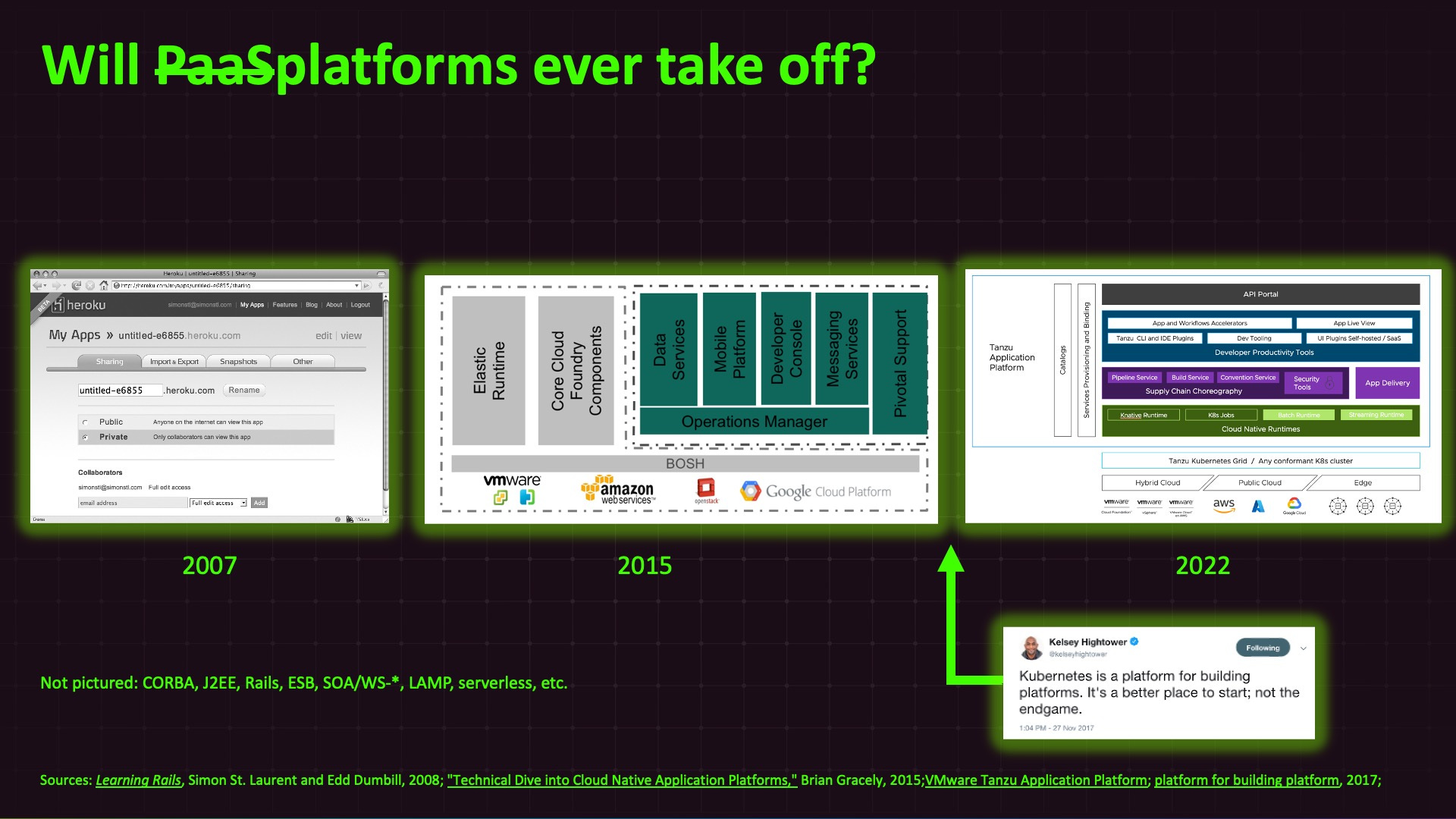
Our old pal kubernetes came in and changed the infrastructure layer, so we cast out the previous infrastructure stack, that leaked up the app layer, and now we’re on the path to rebuild the whole app stack. The leaks are coming from inside the stack! You can see this in a great round-up of the state of platform engineering from Jennifer Riggins. You could do some s///g’ing on that with PaaS and pretty much describe the state and hopes and dreams of the PaaS app stack in 2015.1
We’re just at the start of the post-kubernetes app stack rewrite. It’ll be fun! People will make money, work on cool open source projects, build up their resumes, learn new things, and organizations will get huge benefits. That all happens each cycle. The thing is, in each cycle, things get better! This is the key to avoiding falling into a cynical pit. Each of these cycles improves the developer experience, e.g.:
Based on customer interviews, Forrester calculated the ROI of VMware Tanzu Application Service to be 142%. The study found that with VMware Tanzu Application Service developers were able to deliver revenue-generating applications two weeks sooner, resulting in an additional $6.2 million over a three year period. Study participants reported that with VMware Tanzu Application Service, developers spent less time building and debugging application environments, a decrease in downtime of business critical applications (leading to more than $5.4 million in savings over three years), and a 75% reduction in time spent on deploying security patches.
The only losers are us olds who don’t adapt (or who were not able to cash out and go blog about the disintegration of society from our porches and Porches) and vendors that don’t pump money into new development and acquisitions, getting stuck with old stacks that are only good for the PE love-squeeze.
And, I want to tell you again: I am fine with this. I am not old man yells at clouds here, but old man double thumbs’ing cloud. I EMBRACE THE JOY OF THE GREAT APP STACK REWRITE.
DevX by Devs
What I like about this current cycle - “platform engineering,” sure, let’s call it…why not? - is that it starts with an emphasis on developer collaboration. To use perhaps the most boring sounding category name I’ve encountered in 30 years: “internal developer platforms”; they might as well have called it “portlets.”

At the end of the PaaS cycle when kubernetes table-flipped everything, we started ignoring what was once called ALM and SDLC. Suddenly, developer experience was in crisis. I don’t know why - there were, like, container formats to fight over or some shit. (Arguably, this is very inaccurate: this was also the era where GitHub and VS Code were clearly ascending. I think the app dev people were sort of like “What, wut? But I just learnt Docker! So, uh, I’m kinda busy up here - call me back later when mommy and daddy stop fighting. Peace out!” Anyhow. Moving right along.)
There are many fun goals and JTD’s in platform engineering. At the moment, the most interesting (and helpful) concept in platform engineering is “discoverability.” Inside an organization (not on the Internet) how can you find what other developer teams are doing? How would you even search for those teams on your intranet, let alone find documentation, get started using their stuff, etc.? Like, let’s say you want to find the developer team in your rental agency that handles claims disputes in Germany. Good luck! Discoverability is (as I understand it), the primary origin of Backstage long ago, and it feeds into a lot of what the rest of us are doing.
(Related side-note: it’s a weird miss that all of the vendors who care about “developers” in large organizations [“enterprises”] passed up on acquiring TaskTop. It’s like the glue-and-pipe to suction all this stuff straight into the coronary artery of The Business. Totes cool for Planview, and all - maybe they’re a fun two pack for the i-banker summer interns to throw up on the two-by-twos and toss down consideration-funnels.)
Once you start at the developer layer, you start drilling down towards the infrastructure and finding all these other things to optimize to make developer’s lives easier. Which is cool, and what you want. It’s better than having the infrastrurue people work upwards towards the developer trying to make the developer experience better.
Starting with this focus on app developers is great. And, hopefully, it means app developers are writing the platform for fellow app developers.
While infrastructure developers and app developers are both developers they are very different types of developers. You can see this reflected in the constant layering of network/services meshes that we have. How many times do we need to reinvent the Internet? Where there were once seven layers, once you throw in microservices, then kubernetes networking, servicemeshes…we have to be up to nine or ten overlay networks that, basically, do the same thing…just with different UX for different personas.
In a post Puppet/Chef world,2 the infrastructure people generally agree with this difference in developers: BOSH (and whatever else) and kubernetes weren’t intended for app developers. They are a “box of sharp knives.” As my old pal Andrew Shafer used to say: well, did you expect that building a cloud from the ground-up and then running it would be easy?3
So, as you start drilling down the app stack, you start adding in more and more things you make better for developers. This is where platform engineering has met up with the DevOps and PaaS people down in the coal-mines. They now share the same goals!
Anyhow. I’m tired of typing. There’s a lot of things the olds should value in platform engineering, and there’s a lot of things the platform engineering generation should pull forward from us olds. I get the sense that these two groups need to go off and have some kind of summit where they come out back-slapping least we fall into some kind of NIH drunk-fight time-killer.
(I’ll be evolving my thinking here this year in some talks: coming up next at cfgmgmtcamp, then SCALE, and maybe some more times after that, digging around more on this topic.)
How to Improve Developer Experience: Find and Remove DevToil
Speaking of, are you looking to do all this platform engineering stuff? Well, that means product managing the platform. This means thinking of developers as your customer, which means finding out what they need, the problems they have.
One way to do this is to perform a developer toil audit to find problems and then track how your fixes are going. Check out this free paper I co-wrote going over what developer toil is and how to systematically find it.
Wastebook
“You went full can-of-worms on 'em!”
I should make a podcast one day that just automatically cuts off after ten minutes that’s called The Hard Stop.
My Content
When low code is good, when it’s dangerous, also, $4.5 trillion worth of computer stuff - Tanzu Talk for Jan 19th, 2023 - THIS IS A GOOD EPISODE, FOR REAL. What’s the deal with low code? After discussing current IT spending forecasts, Ed, Ben, and Coté discuss some recent thinking on how low code seems to fit into your business. We also discuss the organization structures needed for doing platform engineering and all that.
Mark as Unread, Software Defined Talk #397 - This week we discuss DHH’s quest to cut HEY’s cloud costs, Chick-fil-A’s use of Kubernetes and some hot takes on Unlimited PTO. Plus, thoughts on champagne….
Relevant to your interests
Matt Yglesias and the secret of blogging - by Max Read - “there is currently no real economic punishment for content overproduction. You will almost never lose money, followers, attention, or reach simply from posting too much.” // I AM TESTING THIS THEORY NOW - lol.
How InnerSource is transforming IBM’s Watson, Bill Higgins (IBM), IS Summit 22 - As we figure out internal developer platforms (IDP), DevX, etc. that this year, inner-sourcing will have a lot to offer. A mature, well understood concept that can slot right in. Here’s my old pal Bill Higgins going over it. And also a bonus insight into Watson development over the past ten years.
Speaking of “PE love-squeeze” 👉 Inside CNET’s AI-powered SEO money machine - “They do not fear AI more than they fear the numerous layoffs Red Ventures has insisted upon,” a former employee says. “Everyone at CNET is more afraid of Red Ventures than they are of AI.”
A story of microservices - Drax Group Accelerates its Carbon-Negative Future - ‘“Microservices requires a different mindset about the design of the best components that allow maximum reusability and independence. We’re taking a ‘learn by doing’ approach where our skills, capabilities and ways of working adapt over time,” says Leonard.’” And: “The Drax Target Architecture has supported the delivery of new, strategically important and growth-enabling services. For example, its solution built on VMware Tanzu technology has enabled the company to launch an industry-leading digital service that provides business customers with greater visibility into—and management of—energy consumption of their electric vehicle fleets. In addition, Drax now has complete visibility into the end-to-end transportation of biomass wood pellets from the US to the UK, using a machine learning layer to reveal vital insights to improve its supply chain and KPI management.”
Rick Rubin on Listening, Taste, and the Act of Noticing (Ep. 169), Conversations with Tyler - This is a really fantastic interview. It’s about music, sure, but it’s also about just a way of thinking, a world-view, almost a way of living.
“The 2022 McKinsey Global Payments Report is available. After a slump in 2020, the industry reached $2.1 trillion (11% growth),” via Bryan.
Google Calls In Larry Page and Sergey Brin to Tackle ChatGPT and A.I. Chatbots - The “why did Google drop the ball?” article I didn’t know I’d been waiting for. Sounds like they’ve been too conservative and driven by what could go wrong (fear) rather than the whiz-bang. // “Google listed copyright, privacy and antitrust as the primary risks of the technology in the slide presentation. It said that actions, such as filtering answers to weed out copyrighted material and stopping A.I. from sharing personally identifiable information, are needed to reduce those risks.” And: ‘Google expects governments to scrutinize its A.I. products for signs of these issues. The company has recently been the subject of numerous government inquiries and lawsuits accusing it of anti-competitive business practices. It anticipates, according to the presentation, “increased pressure on A.l. regulatory efforts because of rising concerns about misinformation, harmful content, bias, copyright.”’// Also a little great man theory in the headline: why would bringing back the long-departed founders do anything?
Drunk Maasdriel city councilor left Shetland pony tied up on Den Bosch terrace - Meanwhile, in The Netherlands // “this is, of course, unacceptable, as every normal thinking person would know.”
Are cows at sea the future of farming? - Dry-land is a myth! - “As a world, we are in such a need to find solutions for the upcoming 30 years,” Peter says. “One of the biggest challenges we come across worldwide is regulations. Cities need to have disruptive thinking. Cities need to have disruptive departments. Cities need to have areas where you can say: OK, this is the experimental zone.”
Logoff
It’s snowing here in Amsterdam. That doesn’t happen much.

Well, that typing up there was a bit of a rant, eh!
To post-script it: what always needs to be said about this platform stuff is that there’s usually people in the previous generation that are perfectly happy and productive with the “old” stuff. For example, pretty much every time I talk with someone at a large organization using Cloud Foundry they say the same thing: “our developers love it. We’re putting kubernetes in place now too” and then they kind of shrug.
I mean, both are fine - to borrow a sentiment from the Rick Rubin interview linked above: “It doesn’t bother me one way or the other. I like music that sounds good.”
Double thumbs up, 💯, word-up fellow kids, et cetera, &c.
See y’all next episode.
Suggested outro to start your weekend with:
This a comment on the article itself, but the trend being wrangled. The article is great!
The IoC people were surprising (delightfully?) app dev friendly at first. I’m not sure what happened, but I rarely encountered an application developer at a DevOpsDays, etc.
I’ve reworded this, but, I mean, same idea.